Yesterday, Andromeda Yelton posted this excellent blog entry, Be Bold, Be Humble: Wikipedia, libraries, and who spoke. It’s about the well-known social sexism dynamic of meetings, where in a meeting that has both women and men, men speak more frequently, use fewer self-undercutting remarks (“I’m not sure….” or “Just…” or “Well, maybe…”), and interrupt others speech at a much higher rate than women in the same meeting.
The post got passed around the social nets (as it should, it’s wonderfully written and you should go read it now) and one of the results was this great exchange:
Which prompted me to reply:
I couldn’t get the idea out of my head, which basically means that it needs to show up here on the blog. I thought all night about how to architect something like that in hardware/software as a stand alone unit. There is always Are Men Talking Too Much?, which Andromeda linked to in her essay, but it has the downside of requiring someone to manually press the buttons in order to track the meeting.
I’ve been basically obsessing over attention metrics for the last couple of years as a part of bringing Measure the Future to life. The entire point of Measure the Future is to collect and analyze information about the environment that is currently difficult to capture…movement of patrons in space. The concept of capturing and analyzing speakers during a meeting isn’t far off, just with audio instead of video signal. How could we built a thing that would sit on a table in a meeting, listen and count men’s vs women’s speaking, including interruptions, and track and graph/visualize the meeting for analysis?
Here’s how I’d architect such a thing, if I were going to build it. Which I’m not right now, because Measure the Future is eating every second that I have, but…if I were to start tinkering on this after MtF gives me some breathing room, here’s how I might go about it.
We are at the point in the progress of Moore’s Law that even the cheapest possible microcomputer can handle audio analysis without much difficulty. The Raspberry Pi 3 is my latest object of obsession…the built-in wifi and BTLE changes the game when it comes to hardware implementations of tools. It’s fast, easy to work with, runs a variety of linux installs, and can support both GPIO or USB sensors. After that, it would just be selecting a good omnidirectional microphone to ensure even coverage of vocal capture.
I’d start with that for hardware, and then take a look at the variety of open source audio analysis tools out there. There’s a ton of open source code that’s available for speech recognition, because audio interfaces are the new hotness, but that’s actually overcomplicated for what we would need.
What we would want is something more akin to voice analysis software rather than recognition…we don’t care what words are being said, specifically, we just care about recognizing male vs female voices. This is difficult and has many complicating factors…it would be nearly impossible to get to 100% success rate in identification, as the complicating factors are many (multiple voices, echo in meeting rooms, etc). But there is work being done in this area: the voice-gender project on Github has a pre-trained software that appears to be exactly the sort of thing we’d need. Some good discussion about difficulty and strategies here as well.
If we weren’t concerned about absolute measures and instead were comfortable with generalized averages and rounding errors, we could probably get away with this suggestion, which involves fairly simply frequency averaging. These suggestions are from a few years ago, which means that the hardware power available to throw at the problem is 8x or better what it was at that point.
And if we have network connectivity, we could even harness the power of machine learning at scale and push audio to something like the Microsoft Speaker Recognition API, which has the ability to do much of what we’d ask. Even Google’s TensorFlow and Parsey McParseface might be tools to look at for this.
Given the state of cloud architectures, it may even be possible to build our gender meeting speech analysis engine entirely web-based, using Chrome as the user interface. The browser can do streaming audio to the cloud, where it would be analyzed and then returned for visualization. I have a particular bias towards instantiating things in hardware that can be used without connectivity, but in this case, going purely cloud architecture might be equally useful.
Besides gender, the other aspect that I had considered analyzing was interruptions, which I think could be roughly modeled by analyzing overlap of voices and ordering of speech actors. You could mark an “interruption event” by the lack of time between speakers, or actual overlap of voices, and you could determine the actor/interrupter by ordering of voices.
Once you have your audio analysis, visualizing it on the web would be straightforward. There are javascript libraries that do great things with charts like Chart.js or Canvas, or if working in the cloud you could use Google Chart Tools.
If any enterprising developer wants to work on something like this, I’d love to help manage the project. I think it could be a fun hackathon project, especially if going the cloud route. All it needs is a great name, which I’m not clever enough to think of right now. Taking suggestions over on Twitter @griffey.
 Source: 3D-printed Drinks
Source: 3D-printed Drinks
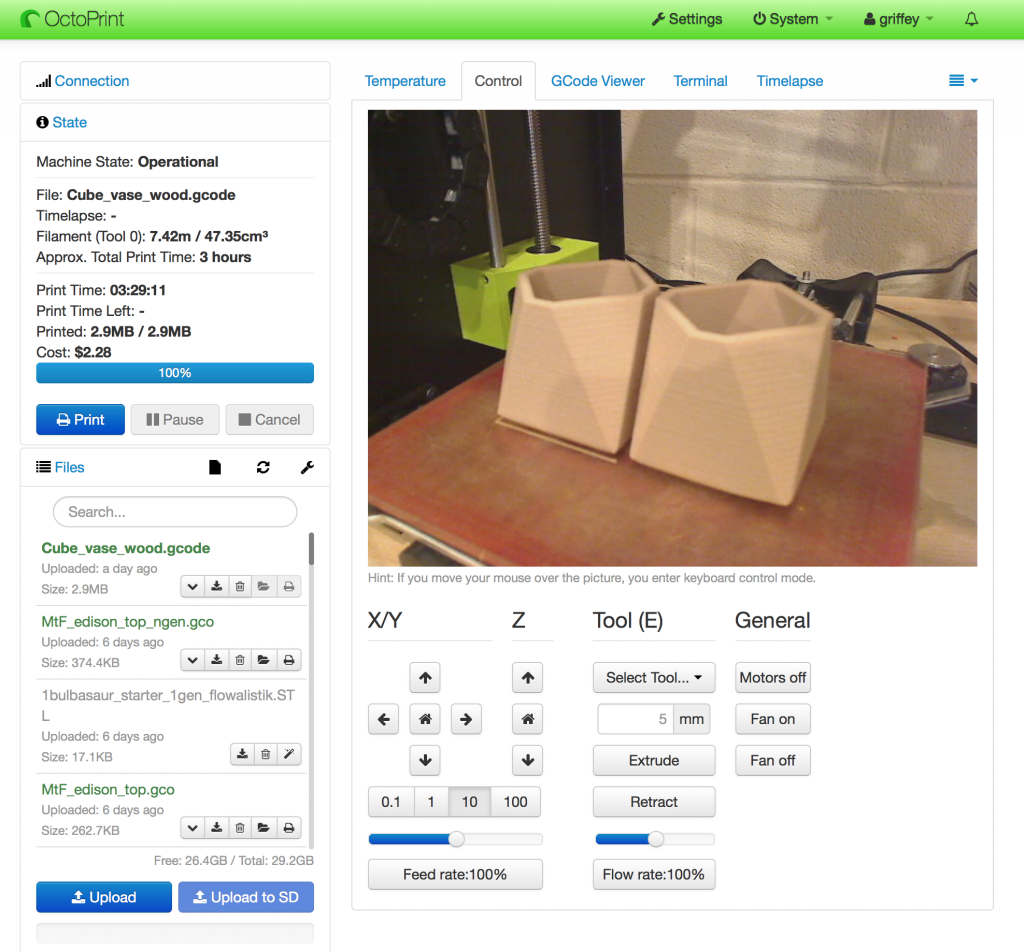 What does Octoprint do? For compatible printers (which includes nearly any that use the industry standard gcode instructions to print), Octoprint can control every aspect of the printer, including:
What does Octoprint do? For compatible printers (which includes nearly any that use the industry standard gcode instructions to print), Octoprint can control every aspect of the printer, including: