Google has made an interesting move with Book Search…they just added a “My Library” component, which allows you to catalog your home library using Google.
Now, if you do a search in Google Books, one of the options is “Add to My Library”

If you click the link, and are logged into Google, it starts your collection:
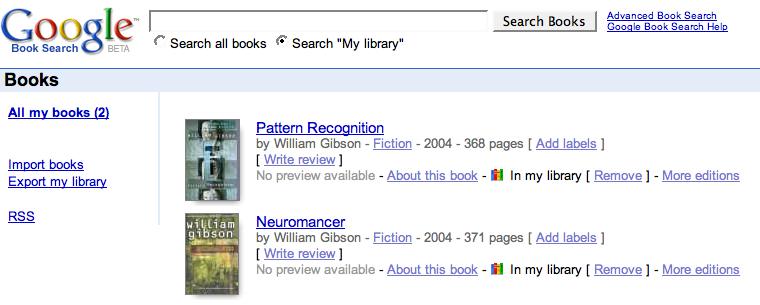
The links on the side give an option to Import/Export you library, but the import options is woefully weak…it only allows you to paste in a list of ISBNs. No CSV or Delimited files, no xml, no other formal metadata. Just ISBNs.
Export is possibly even worse. Google My Library exports an XML file with the following structure:
<book>
<id>drYIAAAACAAJ</id>
<url>http://books.google.com/books?id=drYIAAAACAAJ</ur>
<title>Pattern Recognition</title>
<contributor>William Gibson</contributor>
−
<identifier>
<type>ISBN</type>
<value>0425192938</value>
</identifier>
</book>
Google? What’s with the non-existent metadata? I can do better at Amazon, not to mention a real library tool like LibraryThing.
Google My Library also has the ability to display just the cover view of your library, but there doesn’t appear to be any ordering/sorting options…although it will limit a search to just your library, it would still be nice to be able to order. How about some faceted browsing, Google?
This is an interesting product from Google. It is yet another set of information they can use to target advertisements (if they know the contents of your library and 982734987234 other people, they can cross reference that and target ads). But as a product from the consumer’s view, this seems way less useful than LibraryThing, which has given serious thought to what people want to do with their own books, and gives a nearly obsessive number of tools to the user.
On the other hand, this is Google. They are likely to gather a huge number of users from their existing base, even when there may be better tools out there for the given job. Haven’t seen this over at the Thingology blog…Tim, what do you think about this?



