ElizaCast for March 2007: Eliza Rolls Over!
Categories
ElizaCast for March 2007: Eliza Rolls Over!
In thinking about Michael Sauers recent brilliant post on cataloging Creative Commons works, I’m considering setting up an iTunes instance on our Student network in MPOW. On that system, we could load…well, that’s the crux of this post. Long time readers of this blog know my stance on copyright, and that I keep up with the latest issues, especially vis a vis digital copyright. I could, at the very least, load CC licensed music on this system. But what else?
So, I ask you, blogosphere: What can I legally load on that iTunes instance? It would be openly shared, streamable to anyone connected to our student network…but, as anyone who has used iTunes knows, not downloadable. Can I load the majority of the library music collection on that machine? Why not? If it is legal for me as a private citizen to rip my purchased music to digital form (yes, I realize that not everyone thinks this is legal, but it is the current position held by most copyright thinkers), then why would it not be legal for “me” as a library? Once ripped, can it possibly be illegal for me to use functionality that iTunes has built into it?
Is anyone out there doing this? It would mean that every student could stream any of our music collection from any computer with iTunes as long as they were connected to our network…which would, of course, be any computer in the library (or their own computer).
Once more, oh blogosphere, I ask you: what’s wrong with this idea?
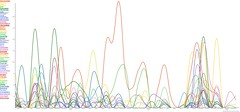
Really amazing graph generated using Lastfm Extra Stats that analyzes my music listening habits for the last 3 years. I’ve been using Last.fm to track my iTunes and other listening, and it’s really cool to be able to drag that data out and see it in graph form.
Very, very cool little program.
Over the course of the last 20 years, there has been a radical shift in the economies of information. We’ve moved from a world in which information was plentiful but distributed and difficult to find to a world where information is even more plentiful, but ubiquitous and easy to find. Libraries are suffering now as a result of their inability of unwillingness to change based on the new method of information indexing, exchange, and archival.
Libraries were a central part of the public sphere because of that information imbalance. Most libraries have moved to a new model that emphasizes access and comfort instead of being the storehouse of knowledge they once were. Access is something that libraries have on their side, because information, in defiance of the normal rules of supply and demand, still insists on being expensive.
Prepare for another shift, because the next 5-10 years is going to change the rules again.
Chris Anderson, in the latest Wired magazine, outlines the next information revolution: Free.
The rise of “freeconomics” is being driven by the underlying technologies that power the Web. Just as Moore’s law dictates that a unit of processing power halves in price every 18 months, the price of bandwidth and storage is dropping even faster. Which is to say, the trend lines that determine the cost of doing business online all point the same way: to zero.
Anderson outlines his argument in the context of business, but his points really show us that the nominal cost of information delivery is the core of the revolution. Of course, the fact that the delivery is free does not immediately mean that the information being delivered is free…that change arises from more traditional competitive pressure. What are traditional information services like books, movies, and television competing with these days? They are competing with free, easily available, highly portable, and in nearly every way more useful unauthorized versions of themselves.
When customers look at the following options, what do you think they choose?
Buying TV shows on iTunes, where they can watch them on their authorized computer and iPods, but not on their Zune or PSP or anywhere else they might want OR downloading a .torrent of their favorite TV show that is higher in quality than the iTunes download that they can watch anywhere they want.
Buying an audiobook from Audible, which has limited playability on only approved devices, or grabbing a P2P copy of that audiobook with no limitations (and no price).
Reading a book on Harper-Collins website, embedded in your browser is one option. Another is the Tor model, where once a week they are providing a free book, in multiple formats (pdf, html, mobi) for you to do with as you will. Move it to an ebook reader. Read it on your computer. Put it on your cellphone. Another option is the library.
It’s obvious that things that are free have an immediate advantage, and libraries have been free for a very long time in the US. But even free vs free has its calculus. If we look at the above examples, it’s very important for libraries to realize that they aren’t competing with iTunes and Audible. They are competing with .torrents and other P2P technologies that disintermediate the information distribution process.
But even free has choices: One example is Hulu, the beta site for NBC/Fox/etc. They pulled their shows from YouTube, citing copyright violations, and launched Hulu, where they can control the message and availability. Then there is OpenHulu, a site that scrapes Hulu and provides the ability to watch the same shows with no login or account creation. Yet another choice is the aforementioned Torrent or other P2P distribution, where there are no commercials, no requirement to stream instead of download, and the ability to watch them on the device of your choice. The advantage of Hulu and OpenHulu over torrenting is instant gratification. Which wins?
So when there are two freely available sources for information, what drives choice? Lots of different aspects of the interaction between the patron and the information make the difference. Ease of use. Availability. Speed. Quality. Brand recognition. Marketing.
Anderson points out that free is the future of commerce, and I absolutely see it as the future of media and information generally. How do libraries then compete in a world where their major advantage is completely nullified? What do we bring to the new information economy, because we need to be planning and implementing now to have any hope of competition.
I think I know some of the ways we compete, but that’s another post. What do you think we can do to stay relevant?
Given my infrequency of posting, its obvious that I’ve been a little busy lately. Mostly it’s been Eliza based, but work is also nuts. This time of year is crazy, and you pile working 3 days a week instead of 5 AND building a new library…well, its a little slice of insanity.
I’ve been so nuts that I completely missed my 5 year Blogoversary!
February 10th, 2003, after an inauspicious start, I started blogging. Five years, 1241 posts, and 1445 comments later, and it’s still going strong. Over the course of those years, I’ve been featured on BoingBoing four times, Digg once, highlighted by the ALA, and it’s led to an enormous amount of opportunity for me.
Pattern Recognition also led directly to being invited to write a book on Library Blogging, which will at long last be out this Spring. Another writing opportunity has presented itself as well, which will be announced in the next few weeks…I’m not at liberty to say quite yet, but if you want to read what I have to say, you’ll have at least one more place you can be sure to see me in 2008.
Most of the above isn’t thanks to anything special I’ve done, but instead thanks to the readers and comments on Pat Rec…thanks to everyone who takes time from their day to read me. I appreciate it more than I can adequately express, and hope that you’re getting some value for your time.
All in all, this crazy blog has done a lot for me. Here’s hoping the next 5 years are as auspicious as the last!
I’m in the middle of reviewing a hosted blogging solution for K-12 called ePals…this is to determine if it needs to be/should be included in Library Blogging. I’m reading through, when I get to a click through license. Every once in a while, I love to read these things to see the insanity they think they can impose…here’s a great example. Check this out:
V. LINKING TO THIS WEB SITE
Unless you have a written agreement in effect with ePals which states otherwise, you may only include a link to an ePals Site on another Web site if:
(a) the link is a text-only link clearly marked “www.ePals.com;”
(b) the link “points” to the ePals’ home page URL and not to other pages within the ePals Site; (c) the appearance, position and other aspects of the link does not damage or dilute the goodwill associated with ePals’ or In2Books’ brand name and trademarks;
(d) the appearance, position and other aspects of the link does not create the false appearance that any entity is associated with or sponsored by ePals;
(e) the link, when activated by a user, displays the Site’s full-screen that is not within a “frame” on the linking Web site; and
(f) the link will not be used in connection with or appear on a Web site that a reasonable person may consider offensive, obscene, defamatory or otherwise malicious.ePals reserves the right to revoke its consent to the link at any time, in its sole discretion. If ePals revokes such consent, you agree to immediately remove and disable any and all links to ePals Sites.
To illustrate this insanity, if I were to, say…link directly to their Email description page, I would be in violation of this license. Or if I link directly to their Blog page…again, in violation.
Can you imagine a Web where people had to request the right to link to something?
Jenny and Michael, in a fit of brilliance, have set up a Win a Wii donation drive for Blake Carver, who runs LISHost, my very favorite internet hosting service. If you read a library-focused blog, there’s a better than average chance that Blake is hosting it…including Pattern Recognition.
So: go and donate, and maybe win a Wii!
Here’s an idea I had today that I wanted to get down so I don’t forget it…autonomous self-checkout with cell phones. Here’s the idea:
You write a web-service that logs the customer into their account from their cell phone browser, and then takes over the camera on their cell. They point the camera at a bar code on the book in question, and you software looks it up in the catalog and checks it out to the patron.
The difficult part for the library is how to enable the deactivation of the security strips that most of us use…ideally, the security system would be tied to the catalog, and would know when a book was checked out and when it wasn’t, and alarm only as appropriate.
This would take library staff completely out of the checkout process (which self-checkout already does) but would ALSO take any specialized equipment out, and allow for nearly complete patron autonomy in the stacks.
The interesting thing is, I’m pretty sure that all of this is possible with current open source software. Certainly there would need to be some development, but I don’t think anything would have to be completely written from scratch…maybe connectors that transfer data from one system to the other.
Thoughts? Is this being done anywhere? Or did I actually have an original thought?
Eliza had yet another friend come into the world…welcome Conrad Ferguson Thomas!
We can’t wait to meet him!